Uno de los primeros casos documentados del uso de Inteligencia Artificial (IA) en el Congreso ocurrió el 30 de junio de 2025 cuando el senador Mario Vázquez Robles (PAN) usó ChatGPT para ensamblar el discurso con el que se opondría a la eliminación de la Cofece. Al ser cuestionado, declaró que la IA le ayudaba a “decir mejor lo que le dictaba su conciencia”.
Esta trama tuvo un segundo episodio el 28 de noviembre de 2025, cuando el mismo senador fue captadoprompteando en su celular: “Vamos a agregar que la salida del fiscal tiene que ver con el huachicol fiscal…”. Al fijar su postura en la discusión plenaria sobre la renuncia de Alejandro Gertz como titular de la Fiscalía General de la República utilizó precisamente ese argumento.
En congresos donde las cargas de trabajo avanzan más rápido que el tiempo parlamentario, los modelos de lenguaje a gran escala (LLM, por sus siglas en inglés) son una opción atractiva. Redactan documentos y recopilan información en segundos, además de servir como asistentes personalizados que los congresistas pueden consultar 24/7 para argumentar como verdaderos especialistas en cualquier tema. Recordemos cómo a mediados de 2025, la diputada Olga Leticia Chávez (Morena) pidió a la oposición “actualizarse” y recomendarles meter las iniciativas a un chat de IA para resumir en 15 minutos, documentos de 200 páginas.
Hasta aquí, todo parecería un simple proceso de adopción tecnológica orientado a hacer más eficiente una función gubernativa. Algo que en principio suena deseable. El problema aparece cuando se reconoce que la IA opera como una capa de mediación entre ciudadanía y representantes. En diciembre de 2022, leyendo el primer discurso generado por IA en la Casa de los Comunes del Reino Unido, el representante Luke Evans, declaró:
Este es un avance increíble, pero conlleva importantes problemas de autonomía, responsabilidad, equidad, seguridad, moralidad e incluso propiedad de la creatividad. En esta Cámara debemos preguntarnos cómo gobernaremos esto.
Su declaración deja claro que la IA es útil para el trabajo parlamentario, pero sólo si se emplea con límites éticos y reglas de responsabilidad. De otro modo, puede desdibujar la relación gubernativa y volver más opaca la rendición de cuentas. No es casualidad que, tras conocer que asambleas en más de 50 países ya habían incorporado la IA para tareas sustantivas, la Unión Interparlamentaria (IPU) emitió en 2024 los lineamientos para el uso de IA en parlamentos.
¿Cómo identificar los discursos asistidos con IA?
Los casos virales y las notas en medios han servido para visibilizar el uso de IA en congresos de nuestro país. Sin embargo, ante la falta de mediciones sistemáticas del fenómeno tanto en México como en América Latina la conversación sigue sustentada en anécdotas.
Hasta ahora, el único ejercicio serio, es un estudio que analizó la frecuencia con la que un conjunto de expresiones que comúnmente genera ChatGPT se incluyeron en discursos de parlamentarios británicos. El análisis permitió concluir que el uso de IA comenzó a incrementarse en Westminster desde 2022 y registró un pico en 2024. Con base en este estudio, hicimos un ejercicio con la Cámara de Diputados en México.
Paso 1. Tribuna artificial
Dado que el estudio británico se hizo con código y diccionarios en inglés, para el caso mexicano primero tuvimos que identificar qué palabras y frases tienden a repetirse cuando la IA redacta discursos en español. Para eso construimos un archivo llamado “tribuna artificial”, generado con prompts estandarizados para ChatGPT y Gemini.
Un ejemplo de prompt fue: “Eres un legislador de Morena. Redacta una intervención en tribuna > 200 palabras, con protocolo parlamentario, sobre turismo, con tono técnico.”
Este diseño nos permitió trabajar en un entorno controlado, fijando variables como registro institucional, sexo de la persona legisladora, partido, tema y tono. Para inducir diferencias ideológicas, incorporamos como insumo las declaraciones de principios de cada partido y, además, ajustamos los prompts para que el número de discursos por fuerza política reflejara su peso en la Cámara de Diputados (LXVI Legislatura, 2024-2027).
Los tonos se distribuyeron entre conciliador, crítico, enfático, moderado, propositivo, reformista, técnico y urgente. Los temas se definieron con base en las 50 comisiones ordinarias. Corrimos en ambos modelos de IA para que el corpus artificial no quedara dominado por el estilo lingüístico de un solo sistema.
Paso 2. Tras las huellas del algoritmo.
Después, definimos un procedimiento para detectar las posibles marcas lingüísticas en textos generados por chats de IA usando tres tipos de señal: 1) palabras; 2) n-gramas (o secuencias fijas de palabras) como “sin embargo” o “en caso de”; y, 3) patrones estructurales como “por un lado… por otro lado…”, “sin… que…”, “más… que…” o “tan… como…”. Antes de hacer los conteos eliminamos fórmulas protocolarias y de trámite, para que las rutinas parlamentarias (ej. “con su venia”, “es cuanto”, etc.) no sesgaran el análisis.
Para seleccionar los mejores candidatos de esa primera lista empleamos dos criterios: a) Cobertura: en cuántos discursos aparecía cada expresión artificial; y, b) Frecuencia relativa: cuántas veces se presentaba por cada mil palabras.
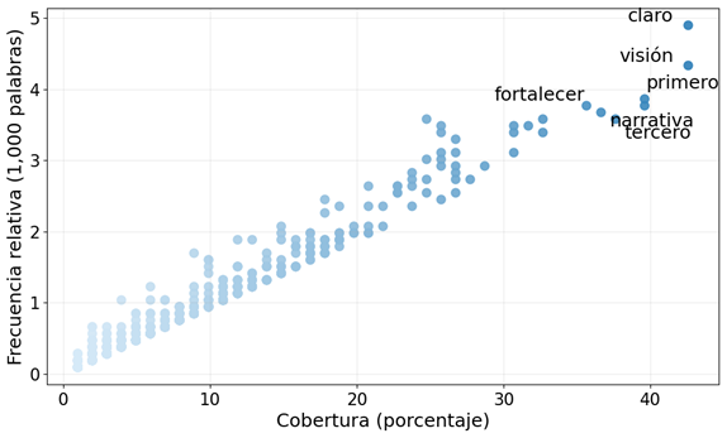
El siguiente gráfico muestra la relación entre cobertura y frecuencia relativa de 2,500 palabras candidatas contenidas en los 100 discursos de la tribuna simulada. Etiquetamos solo algunas de las palabras candidatas con mayor presencia y recurrencia. El mismo procedimiento se aplicó después a n-gramas y patrones estructurales para identificar huellas de IA, más allá del vocabulario. Con ello seleccionamos las expresiones con valores más altos para lograr un catálogo de huellas lingüísticas de IA.[1]
Gráfico 1. Presencia y recurrencia léxica en discursos simulados
Paso 3. Marcas de IA en “discursos naturales”
Con el catálogo listo, evaluamos el uso de estas expresiones en los discursos de diputaciones de la LXVI Legislatura. Para ello descargamos todas las intervenciones del Diario de los Debates del 1 de septiembre de 2021 al 28 de octubre de 2025 (tramo que incluye un periodo previo a la adopción masiva de modelos generativos y la expansión posterior de 2022). Para depurar el material, eliminamos intervenciones de protocolo y procedimiento, para conservar únicamente los discursos pronunciados por diputaciones con más de 120 palabras. Con esto, el archivo final de “discursos naturales” quedó en 13,330 intervenciones expresadas en casi 7 millones de palabras, con un promedio de 510 palabras por intervención.
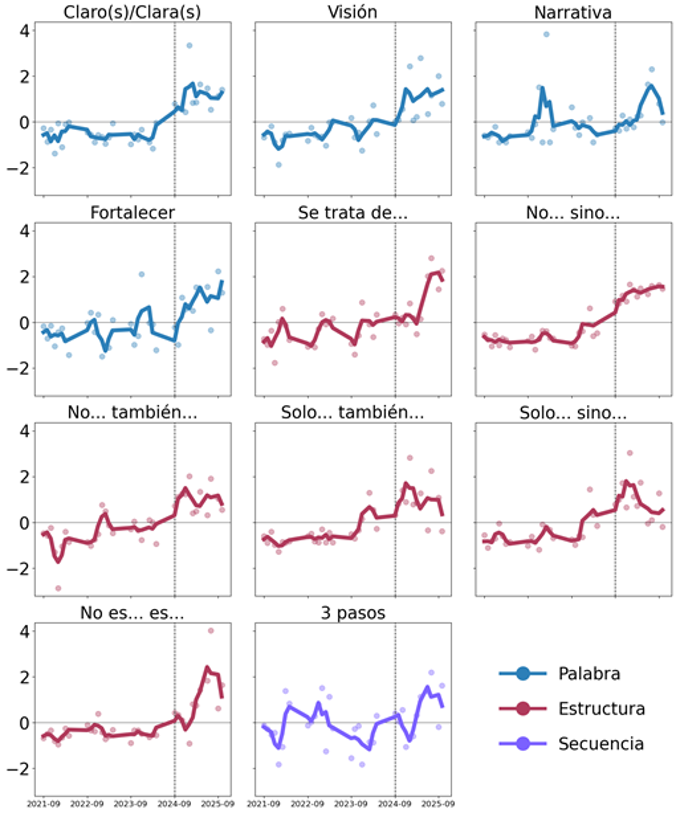
Nuestro primer interés analítico fue ver si las huellas lingüísticas de IA crecieron con el tiempo en los discursos de los diputados. Para ello seguimos su evolución mensual con z-scores por cada mil palabras y comparamos cada mes con el nivel típico del periodo de análisis completo (2021–2025).
En el siguiente gráfico, los valores por encima de la línea horizontal (de cero) indican mayor presencia de huellas de IA en los discursos parlamentarios. Nótese que casi todas las líneas azules (palabras típicas contenidas en textos hechos con IA), muestran un aumento a partir de septiembre de 2024. Desde ese mes, las marcas aparecen alrededor de 70% más que antes. Algo similar ocurre con las líneas rojas del gráfico (estructuras creadas por la IA). Al comparar entre el periodo previo a septiembre de 2024 y el posterior, las huellas de IA aumentan un 60%.
Finalmente, la línea morada del gráfico aparece como “secuencia”. Esto es así porque, tras una revisión manual de los discursos artificiales, observamos que “primero”, “segundo” y “tercero” no eran palabras aisladas, sino fórmulas para ordenar las intervenciones artificiales, un rasgo común en GPT. En este caso, el comportamiento ascendente no fue tan evidente, aunque sí se advierte un ligero aumento en su uso hacia finales de 2024.
Gráfico 2. Evolución mensual de huellas de IA en discursos parlamentarios (Cámara de Diputados, 2021-2025).
Paso 4. Comprobación
Como sabemos que ciertos sellos de IA aparecieron con mayor frecuencia, realizamos una comprobación general. Para ello construimos una medida sintética de estilo que integró los tres tipos de huella (palabras, expresiones y secuencia). Adicionalmente, incorporamos un análisis de los discursos en el Senado (senadurías) para contrastar si la tendencia observada también aparecía en esa cámara. Para más detalles dejamos abajo una nota metodológica sobre la construcción del índice.
Gráfico 3. Evolución mensual de huellas de IA en discursos parlamentarios (Congreso de la Unión, 2021-2025).
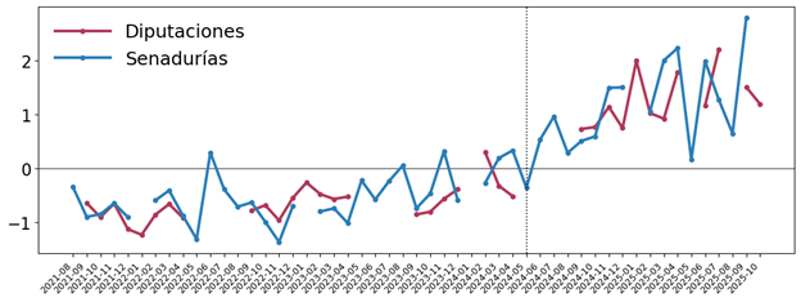
Nota: Las series se presentan únicamente para meses con observaciones efectivas. Los huecos corresponden a periodos de receso o baja actividad deliberativa.
En el gráfico de arriba, los valores positivos indican meses con presencia de sellos de IA por encima del promedio del periodo y los valores negativos, meses por debajo. El patrón confirma un incremento en el índice de marcadores de IA alrededor de septiembre de 2024. En diputaciones, el promedio mensual aumentó en un 70%; además, en intervenciones plenarias del Senado observamos un cambio muy similar. La coincidencia temporal y la replicación del patrón en ambas cámaras apuntan a un cambio significativo en el estilo del discurso de nuestros legisladores federales, con mayor presencia de rasgos que, en nuestra evaluación —nuestra tribuna artificial—, se comportaron como señales típicas de generación asistida.
Una forma de verificar lo anterior es revisar las piezas discursivas concretas donde se encontraron huellas de IA y observar cómo estas se insertan en el discurso. Por ejemplo este fragmento de intervención del 24 de septiembre de 2024 donde una diputada de Morena declara:
“…nuestro presidente no solo ha tenido una política humanista, sino también ha logrado una integración económica como un factor clave para el desarrollo […] el gobierno de México no solo marcó un nuevo capítulo en nuestras relaciones comerciales, sino que también reflejó el compromiso de nuestro país…”.
Dos discursos de un senador del PAN, en noviembre de 2024 usan esa misma estructura para contrastar y escalar afirmaciones. Esta es la primera
“…no son auténticos, son seguidores de corrientes dictatoriales del mundo […] No solo aquí sino también en aquellos países […] No es México, no es Morena, son los países dictatoriales del mundo”.
Y esta es la segunda:
“…no solo amenaza el sustento de miles de familias, sino que compromete […] la sequía no solo es un fenómeno climatológico, es también el resultado de la falta de políticas públicas responsables…”.
Gobernar la IA antes de que ella nos gobierne.
Las líneas que aquí compartimos son el adelanto de una investigación en curso orientada a reflexionar en torno a la incidencia de la IA generativa en la representación política. Nuestra premisa de partida es que, estigmatizar el uso de IA en los congresos sirve de poco, porque su adopción ya es masiva y seguirá creciendo dentro y fuera de estas instituciones.
Sería ingenuo sorprendernos de que nuestros legisladores consulten chats de IA generativa cuando su uso ya se ha masificado en la región. Tan sólo en México, un país con más de 100 millones de usuarios de internet, una proporción mayor al 30 por ciento reporta usar la IA como apoyo en su trabajo y seis de cada diez personas la consideran determinante para su futuro profesional.
La evidencia comparada sugiere que la discusión ha llegado a una escala de no retorno. En congresos locales de Estados Unidos, la NCSL Survey reportó en 2024, que 20% de legisladores admitía que ellos o su staff usaban IA en tareas parlamentarias cotidianas; en 2025, esa proporción subió a 30%. Por otra parte, en 2024, 33% consideraba usarla en el futuro, mientras que en 2025 subió a 38%. Finalmente, en 2024, en 57% de los casos operaba sin reglas o políticas éticas y para 2025 todavía eran 45% de los congresos.
Nuestros resultados para el caso mexicano muestran que después de septiembre de 2024, algo cambió en el debate de ambas cámaras federales. Se trata de un quiebre estadísticamente consistente que sugiere que el Congreso de la Unión podría estar ya operando en un modo híbrido, en el que una proporción creciente del discurso público se construye con asistencia algorítmica.
Insistimos en que el problema de fondo no es que se emplee esta tecnología en la labor parlamentaria, sino en que se incorpore sin reglas, sin trazabilidad y sin capacitación a legisladores y a su staff. En distintos congresos del mundo ya existen manuales de buenas prácticas y políticas internas para ordenar el uso de la IA. La mayoría de ellas recomiendan guardar un registro de los prompts usados y piden que el contenido generado pase por humana para evitar la difusión de información falsa o sesgada. Otros parlamentos tienen sistemas propios que permiten reducir riesgos de filtración de información sensible al alimentarse de jurisprudencia y legislación propia.
En México un marco regulatorio así aún parece distante y el costo puede ser alto porque los poderes legislativos, tanto locales como federal, ya operan con niveles muy bajos de confianza pública. En un contexto en el que se usan algoritmos para la creación de discursos y la toma de decisiones, la ya frágil confianza en diputados y senadores puede erosionarse todavía más. El riesgo es especialmente delicado en debates de alta sensibilidad política, como la discusión que ahora se desarrolla sobre la reforma electoral.
Hannah F. Pitkin sostenía que representar es actuar en nombre de otros bajo una voluntad identificable. El uso de IA desdibuja esta voluntad, diluyendo la voz del representante en formulaciones genéricas optimizadas por una máquina. Por su parte, Bernard Manin afirmaba que la legitimidad de las leyes resultaba de la confrontación de premisas mediante el contraste de la evidencia desde visiones divergentes.
El riesgo de que nuestros representantes recurran a modelos de IA sin capacitación ni gobernanza puede derivar en debates sin revisión profunda de los expedientes ni contraste serio de posturas. Esto le abre la puerta a sesgos que los modelos arrastran desde su entrenamiento y a alucinaciones que podrían colarse en el articulado de las leyes que nos gobernarán a todos.
Nota sobre la construcción del índice de medición de huellas de IA
Para cada intervención  , contamos las ocurrencias de cada marcador de IA
, contamos las ocurrencias de cada marcador de IA 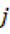 . CY como estos conteos crecen mecánicamente cuando el discurso es más largo, los mantuvimos como tasas por cada 1,000 palabras. Así, si
. CY como estos conteos crecen mecánicamente cuando el discurso es más largo, los mantuvimos como tasas por cada 1,000 palabras. Así, si 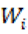 es la longitud del discurso, y
es la longitud del discurso, y 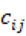 el conteo crudo del marcador, definimos:
el conteo crudo del marcador, definimos: 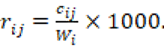
A partir de estas tasas construimos un índice ponderado por discurso. Sea 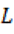 el conjunto de marcadores léxicos (palabras);
el conjunto de marcadores léxicos (palabras); 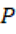 el conjunto de patrones estructurales (frases y construcciones); y
el conjunto de patrones estructurales (frases y construcciones); y 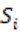 a la secuencia argumentativa de “primero…segundo…tercero…”, el índice se definió como:
a la secuencia argumentativa de “primero…segundo…tercero…”, el índice se definió como: 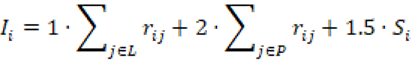
Para la ponderación seguimos un criterio donde las palabras individuales recibieron un peso de 1 porque pueden aparecer en discursos humanos sin implicar una plantilla retórica. Los patrones estructurales recibieron peso 2 porque capturan construcciones retórico-sintácticas más consistentes y menos atribuibles al azar. Y la secuencia 1º, 2º, 3º, se ponderó con 1.5 por reflejar una plantilla reconocible, aunque menos específica que las estructuras. Después agregamos el índice a nivel mensual calculando el promedio por discurso. Para cada mes 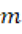 , con conjunto de discursos
, con conjunto de discursos 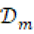 , obteniendo:
, obteniendo: 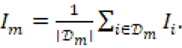
Para comparar meses en una escala común, nuevamente estandarizamos la serie con puntajes z: 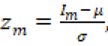 donde
donde 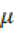 y
y 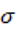 son la media y la desviación estándar del índice mensual en todo el periodo.
son la media y la desviación estándar del índice mensual en todo el periodo.
Sergio A. Bárcena
Fundador de Buró Parlamentario y Profesor-Investigador de la Escuela de Humanidades y Educación del Tecnológico de Monterrey
Javier A. Carrillo
Estudiante de la Licenciatura en Gobierno y Transformación Pública en el Tec de Monterrey
[1] El catálogo de huellas lingüísticas de IA sería: “claro”, “visión”, “primero”, “segundo”, “tercero”, “narrativa” y “fortalecer”; “se trata de”; “no_<X>sino<Y>”, “no_<X>tambien<Y>”, “solo_<X>tambien<Y>”, “solo_<X>sino<Y>” y “no_es_<X>es<Y>”.